NNabla NAS
Neural Network Librariesを用いた構造自動探索(NAS)が実行可能なフレームワーク、NNabla NASがついに公開されました!
Neural Network Librariesのエコシステムに新たに加わるこのNNabla NASによって、みなさんがアプリケーションやプロダクトにニューラルネットワークを導入する際に、ネットワークのデザインやその開発・学習をより簡単・効率的に行うことができるようになることを期待しています。
NNabla NASの開発は現在盛んに行われており、今後も最先端の手法の導入を積極的に続けていくことで、より幅広い応用が可能なフレームワークとなることを目指しています。NNabla NASをより良いものにするため、みなさんのフィードバック・コントリビューションをお待ちしています!
構造自動探索 (Neural Architecture Search, NAS)とは、ニューラルネットワークのネットワーク構造を自動でデザインする手法です。
従来の機械学習においては、特徴量やカーネルの設計は専門家に頼っており、そのためには解くべきタスクに対する詳細なドメイン知識が必要でした。
ディープニューラルネットワークの登場は、そういった専門知識を要する作業をいわば時代遅れのものとし、機械学習における人間の作業を特徴量設計やカーネル設計からネットワーク設計へと変えたことで、1つのパラダイムシフトを起こしたと言えます。
しかしながら、実際にはネットワーク設計もまた時間と労力を要する作業であり、最大限の効果を得るためには慎重な設計が必要不可欠です。これもまた専門知識や経験、そして直感が必要になってくるのが実情となっています。
NASのアルゴリズムはこのネットワーク設計のプロセスを自動化します。すなわち、NASはニューラルネットワークのパラメータを最適化するだけでなく、ネットワークの構造自体も最適化してしまうのです。つまり、ネットワーク内でどのような演算レイヤーを利用するか、そしてそれらをどのように繋げていくかといった構造のデザインを自動で行ってくれるのです。それゆえ、NASはプロダクトにニューラルネットワークを利用する際、本来は必要となる専門知識といったコストを大幅に削減することのできる大変有用なツールです。
通常、NASは3つのステップからなります。
1) サーチスペースの定義
2) ネットワーク構造の最適化(アーキテクチャパラメータの最適化)
3) 探索によって得られた最適とされるネットワークの再学習
サーチスペースとは、組み合わせとして発生し得るすべてのネットワーク構造の集合であり、NASはこのサーチスペースの中で最良とされる構造を探索します。通常、サーチスペース内には数万から数十万の異なるネットワーク構造が存在し、そこからサンプリングされた構造が次々にNASのアルゴリズムで学習・評価されていきます。このように、サーチスペース内には膨大な数のネットワークが存在し、それらのネットワークを学習していくことは計算量的に非常に困難な問題です。これを現実的な時間で行うために、現在様々なNASのアルゴリズムが提案されています。
NNabla NASでは最先端のNASアルゴリズムである、DARTS [Liu18]、およびハードウェア・アウェアな構造探索が可能なProxyless NAS [Cai19]を利用することができます。ここでいうハードウェア・アウェアな構造探索とは、ニューラルネットワークによる推論を実行するデバイス上において、ユーザーが求めるレイテンシやメモリ使用量といった制約を満たすような最適なネットワーク構造を自動で見つけてくれることを意味します。
すぐにでもこのNASを始めることができるように、NNabla NASでは様々な画像認識用データセットに対して試すことができるたくさんの(ハードウェア制約あり)構造自動探索の例を提供しています。
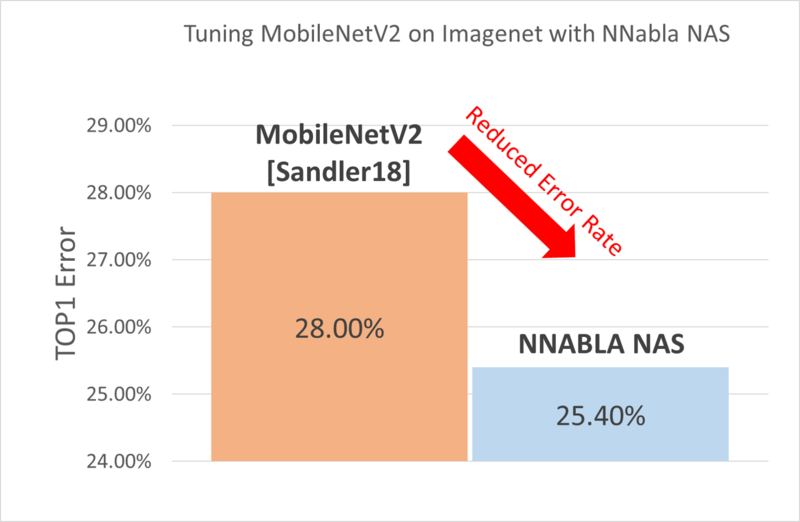
NNabla NASには最先端のNASアルゴリズムが実装されており、たとえばMobileNetV2 [Sandlers18]において用いられているアーキテクチャデザインをベースに、expansion factorやカーネルサイズ、Inverted Residual Blockの数などを最適化した新しいアーキテクチャを探索することも可能です。Proxyless NASアルゴリズムのおかげで、ImageNetのような大規模データセットに対しても直接(代理となる小規模データセットを用いることなく)最適なネットワーク構造を探索することができます。探索の結果得られるネットワーク構造はオリジナルのMobileNetV2に比べて大幅に低いエラー率を記録したうえ、ImageNetを利用しているにも関わらず、学習にかかった時間はわずかに2日でした(4GPUによる学習時)。
リソース
- Documentation: https://nnabla-nas.readthedocs.io/en/v0.9.0/introduction.html
- Docker Images: ——
- Code: https://github.com/sony/nnabla-nas
- Python Package hosted on PYPI, install with:
pip install -U nnabla-nas
主な特徴
サーチスペース
- サーチスペースをフレキシブルに定義可能です。
- サーチスペースから効率的/高速にネットワーク構造をサンプリングすることが可能です。
- ネットワーク構造の候補として利用可能な定義済みモジュールを多数用意しています(例: inverted residual blocks, drop path, dilated depthwise separable, factorized reduction layerなど) 。
探索アルゴリズム
- アーキテクチャパラメータとモデルパラメータの探索アルゴリズムとして
DartsSearcherおよびProxylessNasSearcherが選択可能です。
ハードウェア制約
NNabla NASの重要な特徴の1つとして、ハードウェア制約を考慮した上でネットワーク構造を探索できることが挙げられます。
* 探索時にレイテンシ制約、もしくはメモリ制約を課すことが可能です。
* NNabla NASはレイテンシ評価の際、CPU/GPUに対してはオンラインでプロファイリングを行い、他のデバイスに対してはオフラインでプロファイリングを行います(ルックアップテーブルを利用)。
その他の特徴
- 学習などのログや可視化にTensorboardが利用可能です。
- ネットワークやサーチスペースのグラフ構造を可視化することが可能です。
- マルチGPUサポートをしています。
- NVIDIA DALIを利用したImage Augmentationをサポートしています。
クイックスタート
インストール
まずはNNablaのインストールが必要となります。NNablaのインストール方法に従い、マシン環境に応じたNNablaをインストールしましょう。
次の例はマシンにCUDA 10.2がインストールされている場合の例です。
pip install -U nnabla-ext-cuda102
NNablaのインストールが完了後、NNabla NASも、同様にpipを使って簡単にインストールすることができます。
※NNabla NASのインストールにはPythonのバージョンが3.6以上である必要があります。
pip install -U nnabla-nas
DARTS Architecture Search
以下のようなシンプルなスクリプトで、DARTSを利用した構造自動探索を実行することができます。
import nnabla as nn
from nnabla.ext_utils import get_extension_context
from nnabla_ext.cuda import StreamEventHandler
from nnabla_nas import runner
from nnabla_nas.utils.helper import CommunicatorWrapper
from nnabla_nas.contrib.classification import darts
from args import Configuration
# set the hyper parameters
hparams = {'batch_size_train': 64,
'batch_size_valid': 64,
'mini_batch_train': 16,
'mini_batch_valid': 16,
'epoch': 50,
'search': True,
'target_shapes': [[1]],
'algorithm': 'DartsSearcher',
'config_file': 'examples/classification/darts/cifar10_search.json',
'output_path': 'log/classification/darts/cifar10/search',
'device_id' : 0,
'context': 'cudnn',
'device_id': '0',
'type_config': 'float'}
# split the training set in half for training model and architecture params
data_params = {'train_portion': 0.5}
# set model params training optimizer
train_opt_params = {'grad_clip': 5.0,
'lr_scheduler': 'CosineScheduler',
'weight_decay': 0.0003,
'name': 'Momentum',
'lr': 0.025}
# set architecture training optimizer
valid_opt_params = {'grad_clip': 5.0,
'weight_decay': 0.0003,
'name': 'Momentum',
'lr': 0.025}
# setup context for nnabla
ctx = get_extension_context(hparams['context'],
device_id=hparams['device_id'],
type_config=hparams['type_config'])
hparams['comm'] = CommunicatorWrapper(ctx)
hparams['event'] = StreamEventHandler(int(hparams['comm'].ctx.device_id))
nn.set_default_context(hparams['comm'].ctx)
# set configurations
config={}
config['dataloader'] = {'cifar10' : data_params}
config['optimizer'] = {'train' : train_opt_params, 'valid' : valid_opt_params}
config['hparams'] = hparams
conf = Configuration(config)
# generate darts search space
model = darts.SearchNet(in_channels=3, # RGB input
init_channels=16, # output of the first convolution
num_cells=8, # number of cells of the darts search space
num_classes=10, # CIFAR10 has 10 classes
shared=True) # share architecture parameters between cells
# start the search
runner.DartsSearcher(model,
optimizer=conf.optimizer,
dataloader=conf.dataloader,
args=conf.hparams).run()
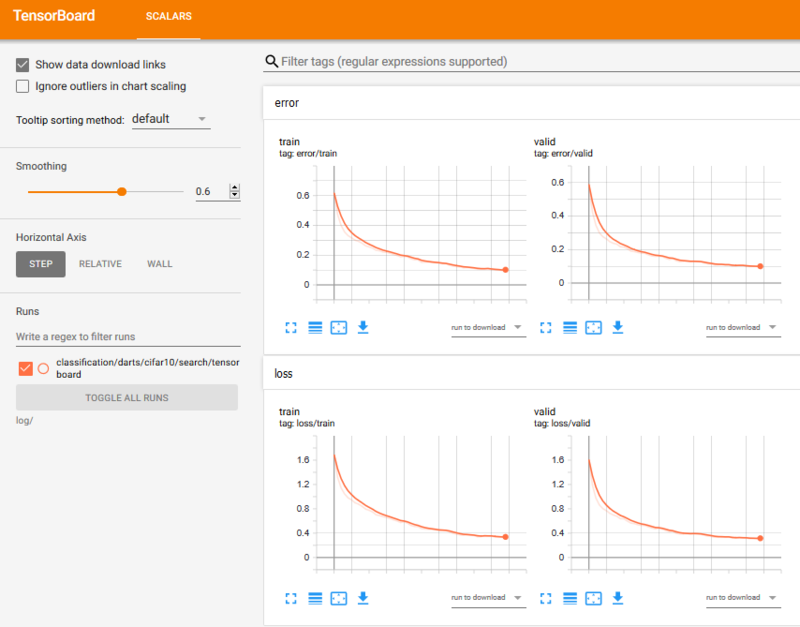
モニタリング
Tensorboardによってモニタリングが可能です。
tensorboard --logdir='log/'
(最初のEpoch以降ログが記録されます)
TensorBoardの詳細については以下のページをご覧ください。
https://www.tensorflow.org/tensorboard/get_started
参考文献
[Cai19] Cai, Han, et al. “On-device image classification with proxyless neural architecture search and quantization-aware fine-tuning.” Proceedings of the IEEE International Conference on Computer Vision Workshops. 2019.
[Liu18] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. “Darts: Differentiable architecture search.” arXiv preprint arXiv:1806.09055 (2018).
[Sandlers18] Sandler, Mark, et al. “Mobilenetv2: Inverted residuals and linear bottlenecks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.