今回は、nnablaで計算グラフ(ネットワーク)を構築する際に、
get_unlinked_variableを利用して部分グラフを切り離して利用するための方法を解説しようと思います。
こちらは、nnablaでのニューラルネットワーク構築の基本的な考え方を理解している方向けの少々アドバンストな話題のご紹介となります。
もしnnablaの基本的な使い方や考え方をお知りになりたい方は、
Neural Network Libraries Step by Step 1
NNabla by Example
などが参考になりますので、是非ご覧になってください。
nnablaのドキュメントで検索してみると、
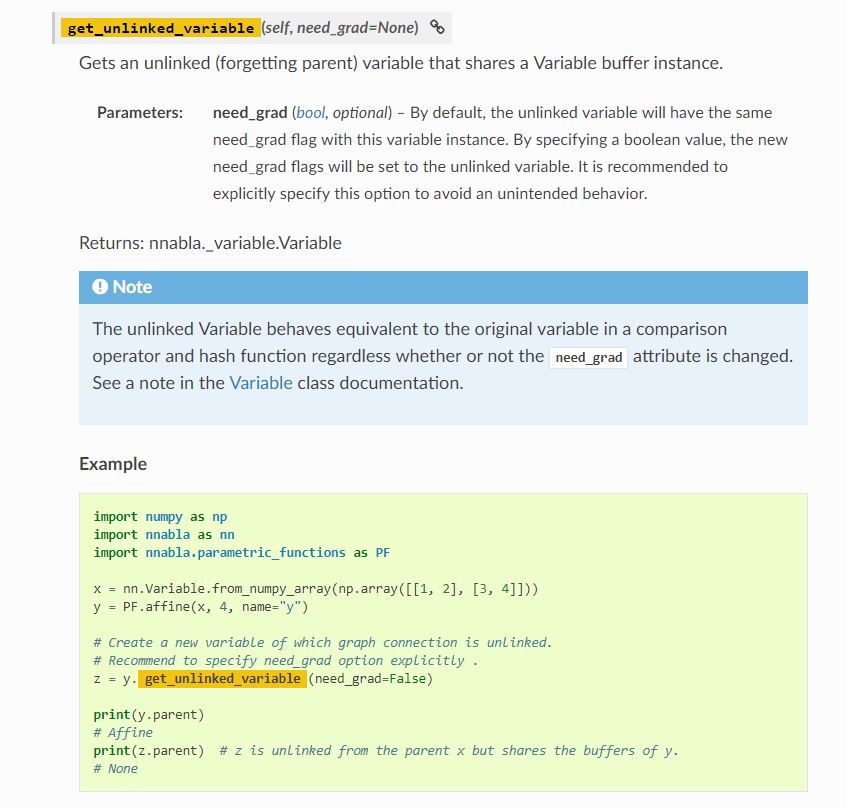
↑このような説明とコード例が出てきます。
説明文を直訳すると、
「このVariableとバッファ領域を共有した、親とつながっていない(新たな)Variableを得る」
という風に読めますが、
これだけでは機能や使い道に正直ピンと来ない人も多いのではないでしょうか。
ここでは、簡単な例を利用して、
get_unlinked_variableが実際には何をしているのか、説明しようとおもいます。
例えば以下のようなコードによって計算グラフを構築してみたとします。
import nnabla as nn
x = nn.Variable(shape=input_shape)
z = model1(x)
y = model2(z)
ここで、model1やmodel2などは抽象化したニューラルネットワークモデルを表しており、
入力を受け取って任意のparametric_functionsやfunctionsなどを適用することで、
グラフを構築する関数を想定しています。
一例を以下に挙げますが、どのようなものでも構いません。
import nnabla.functions as F
import nnabla.parametric_functions as PF
def model(x):
h = PF.convolution(x, ...)
h = F.relu(x)
...
# apply some PF and F to input x
return h
さて、このようにx→z→yと構築すると、以下のようなイメージの計算グラフができあがります。
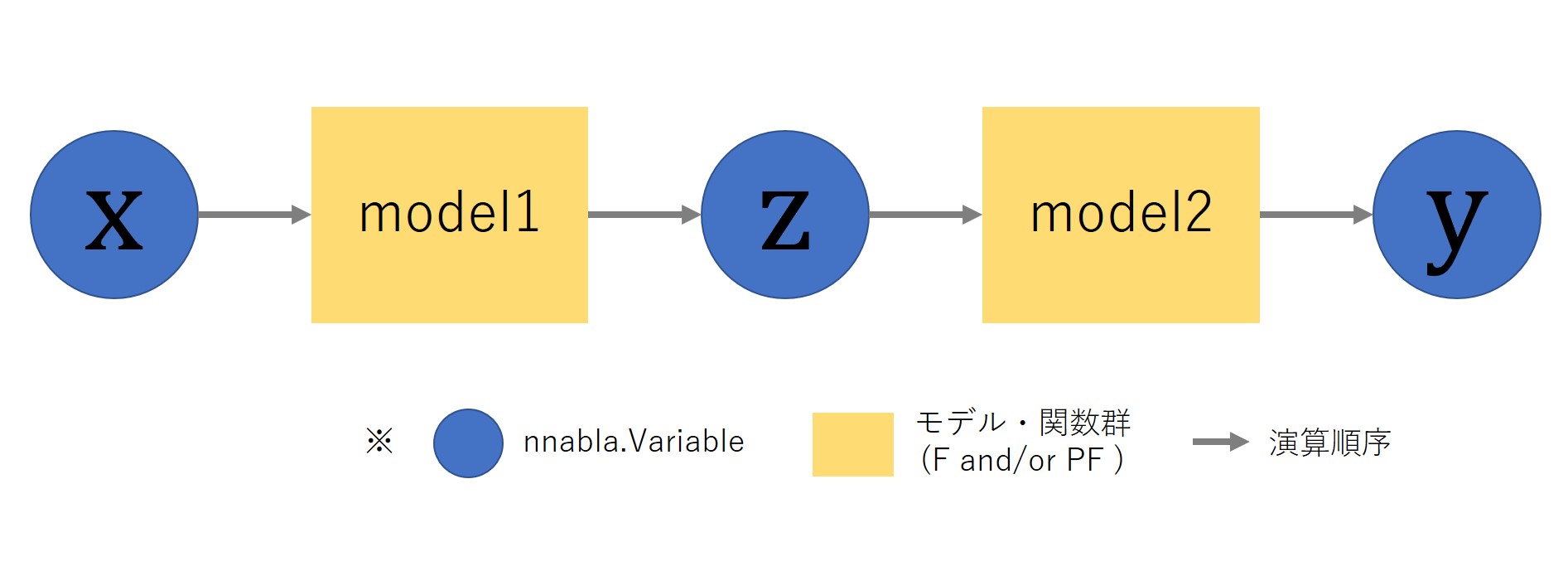
厳密には、model1/model2は、内部にいくつもの関数とVariableを持っていることになりますが、
ここでは説明に必要な最小セットとして簡略化して描画しています。
また再度となりますが、
ここで利用しているmodel1/2は任意のモデルを利用できます。
例えばいくつか例を挙げると、
model1がEncoder、model2がDecoderとすれば、この計算グラフはEncoder-Decoderモデルを、
またはmodel1をGenerator、model2をDiscriminatorとすれば、GANのモデルを構築していると考えることができます。
このグラフのそれぞれのVariableに対して、
forward()やbackward()を呼び出したときの計算実行部分は以下のようになります。
z.forward() #x -> model1 -> z のforward計算
z.backward() #z -> model1 -> x のbackward計算
y.forward() #x -> model1 -> z -> model2 -> y のforward計算
y.backward() #y -> model2 -> z -> model1 -> x のbackward計算
ここで、同じzに対して複数回model2を計算したいケースを考えてみます。
これは一部のGANなどに出てくるケースで、
生成結果であるzは共通でもGeneratorとDiscriminatorに定めるlossが違うケースなどが該当します。
上記の4つのAPI呼び出しを見てみると、
z->model2->yを計算する場合には、y.forward()やy.backward()を呼ぶことになりそうですが、
その場合には本来不必要なx->mode1->zの演算が重複して起きてしまうことになります。
(同じzに対してmodel2を複数回計算したい場合、x->model1->zは一度だけ計算すればよいはずです。)
このような問題点をget_unlinked_variableを利用することによって解決することができます。
以下のようにget_unlinked_variableを利用することによって、グラフをx->model1->z と z->model1->yに分離してみます。
import nnabla as nn
x = nn.Variable(shape=input_shape)
z1 = model1(x)
z2 = z1.get_unlinked_variable() # <-これ
y = model2(z2)
このように構築したグラフは以下のようなイメージとなります。
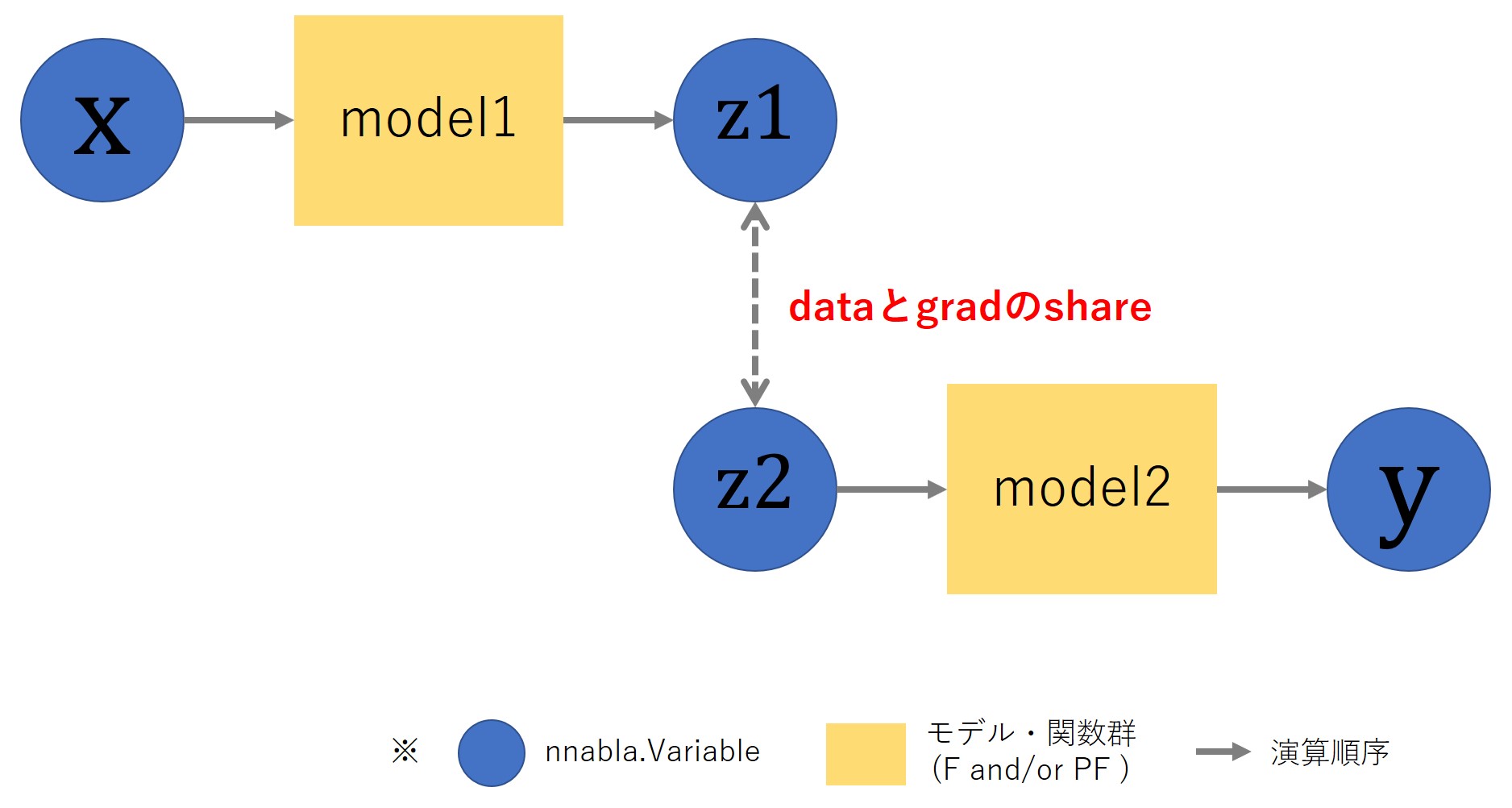
get_unlinked_variable()によってVariableを複製し、
先ほどのグラフを2つのグラフに分離しています。
このunlinked_variableの特徴は、
- z1とz2に計算グラフ上のつながりはない(unlinked)
- z1とz2はdataとgradの領域を共有する(バッファーを共有している)
という点です。
このx, z1, z2, yに対して、
forward()やbackward()を呼び出したときの計算実行部分は以下のようになります。
z1.forward() #x -> model1 -> z1 のforward計算
z1.backward() #z1 -> model1 -> x のbackward計算
z2.forward() #runtimeError (The Variable has no parent)
z2.backward() #runtimeError (The Variable has no parent)
y.forward() #z2 -> model2 -> y のforward計算
y.backward() #y -> model2 -> z2 のbackward計算
まず注目したいのは、yのforward()とbackward()の挙動です。
get_unlinked_variableを利用しなかった例では、
yについてforward()とbackward()を呼び出した際にxからyまでのグラフ全体が計算されていましたが、
今回はget_unlinked_variableによって切り離したz2からyまでに限定されています。
これが「z1とz2に計算グラフ上のつながりはない」ということに相当し、
もともと1つのグラフだったものが、x->z1とz2->yのふたつのグラフに分離されたことを意味します。
しかしこのままでは、
単純に2つのVariableを作成してグラフを構築する場合と何が違うのか、と思う方がいるかもしれません。
このようなケースとの違いは、
unlinked_variableは「z1とz2はdataとgradの領域を共有する」というところにあります。
「z1とz2はdataとgradの領域を共有する」というのは、
言い換えれば、z1とz2はforward()やbackward()などの計算結果を共有して持っている、ということです。
すなわち、以下のような関係が成り立ちます。
z1.forward() #x -> model1 -> z1 のforward計算
assert(z1.d == z2.d) # xからz1に対して計算したforward結果をz2も持っている。
y.backward() #y -> model2 -> z2 のbackward計算
assert(z1.g == z2.g) # yからz2に対して計算したbackward結果をz1も持っている。
これは、二つのVariableを利用してグラフを構築した場合には実現できません。
無理やり同様のことをやろうとすることも可能ですが、
その場合にはz1とz2の間で不必要なデータ転送が起こってしまい、
GPU等のCPUとは別のデバイスで実行しているケースではクリティカルな速度劣化を引き起こしてしまう可能性があります。
最後に、このget_unlinked_variableを利用して効率的に計算を実行する例として、
GeneratorとDiscriminatorを交互最適化するAdversarial Training(GANの学習)を取り上げてみます。
# G: Generator, D: Discriminator, G_loss: Generatorのloss, D_loss: Discriminatorのloss
# GeneratorとDiscriminatorの更新に同じ生成結果を利用する。
x = nn.Variable(shape=...)
real_z = nn.Variable()
fake_z = G(x)
unlinked_fake_z = fake_z.get_unlinked_variable()
g_loss = G_loss(D(unlinked_fake))
d_loss = D_loss(D(real_z), D(unlinked_fake))
...
# 構築したグラフの疑似コード
# ① x -> [G] -> fake_z
# |
# (share data & grad)
# |
# ② unlinked_fake_z -> [D] -> [D_loss or G_loss] -> d_loss or g_loss
for training_iterations:
fake_z.forward() # ①のforward実行
d_loss.forward(clear_no_need_grad=True) # ②のforward実行、Generatorのforwardは起きない
d_loss.backward(clear_buffer=True) # ②のbackward実行、Generatorのbackwardは起きない
solver_d.update()
g_loss.forward(clear_no_need_grad=True) # ②のforward実行、Generatorのforwardは起きない
g_loss.backward(clear_buffer=True) # ②のbackward実行
fake_z.backward(grad=None) # ①のbackward実行
solver_g.update()
trainingループの中でコメントしたところで無駄な計算を省くことができ、
最小の必要計算量で学習を行うことが可能となります。
今回は、get_unlinked_variableに注目して、部分グラフを構築する方法をご紹介いたしました。
少々アドバンストな内容となっておりますが、
痒い所に手が届く機能として、参考にしていただければ幸いです。