NNabla NAS
We are delighted to announce the release of NNabla NAS, the Neural Architecture Search framework for NNabla.
We hope that this new member of the NNabla ecosystem will help you to design and develop Neural Networks for you applications and products in an easy and efficient way. We are actively developing NNabla NAS, improving its usability, adding latest research methods and expanding its range of applications. To improve NNabla NAS, we welcome your feedback and your contributions to the project.
Neural Architecture Search (NAS) refers to methods that can automatically design neural network architectures.
Conventional machine learning algorithms relied on feature and kernel engineering to learn complex nonlinear
properties of dependence. Therefore, they required detailed domain knowledge. The application of Deep Neural Networks (DNNs) rendered such detailed domain knowledge obsolete and caused a shift of paradigm, away from feature and kernel engineering towards network engineering. In practice, network engineering can be a laborious and very time consuming task that must be performed with great care in order to get the maximum performance and efficiency. It requires much expertise, experience and intuition.
NAS algorithms automate the network engineering process. More specifically, a NAS algorithm does not only optimize the DNN parameters, but also the structure of the DNN itself, i.e., what kind of layers are used in the DNN and how they are connected. Therefore, NAS is a powerful engineering tool for machine learning that can significantly reduce the cost and expertise that is needed to successfully apply DNNs in your product.
Typically, NAS involves three steps:
1) The definition of a search space.
2) The optimization of the structure of the network (optimization of the architecture parameters).
3) Retraining of the optimal network architecture to find the best model parameters. The search space is a set of candidate networks on which the architecture search is performed. Typically, it consists of tens or hundreds of thousands of different network architectures, that are sequentially trained and evaluated by the NAS algorithm. Because of this huge size of the search spaces and because training of candidate networks is computationally complex, the main problem of NAS algorithms is to run them in reasonable time.
NNabla NAS implements state-of-the-art algorithms like DARTS [Liu18] and Proxyless NAS [Cai19] for hardware aware neural architecture search. Hardware aware means, that the algorithms can automatically find the optimal network architecture for a given task, that does not violate a given latency constraint or memory budget on a given target device.
To provide an easy starting point, NNabla NAS contains many examples for hardware aware neural architecture search on different image recognition datasets.
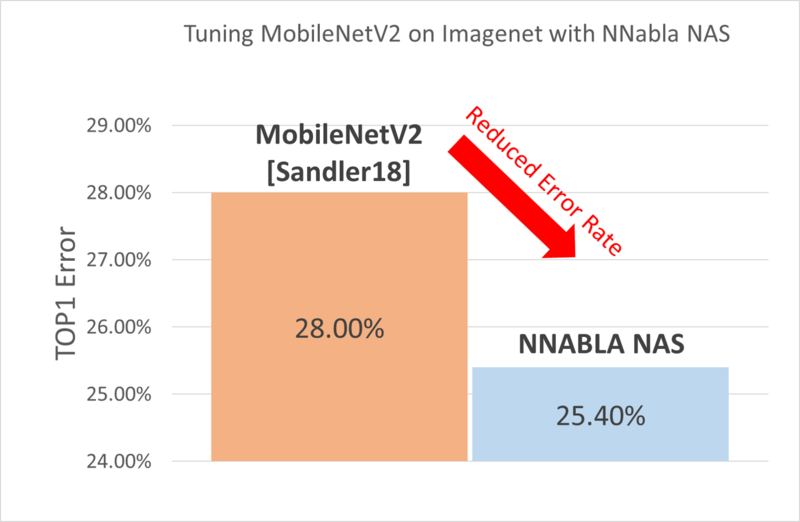
We have implemented several state-of-the-art NAS algorithms with NNabla NAS. We can, for example, search a new architecture based on the architecture design principles set in MobileNetV2 [Sandlers18], while optimizing the expansion factors, kernel sizes and number of inverted residual blocks. Thanks to the Proxiless NAS algorithm [Cai19] we can search the optimal architecture directly on big datasets like the Imagenet dataset. The resulting architectures have a significantly lower error rate than the original MobileNetV2 network, while the search only takes 2 days on Imagenet, using 4 GPUs in parallel.
Resources
- Documentation: https://nnabla-nas.readthedocs.io/en/v0.9.0/introduction.html
- Docker Images: ——
- Code: https://github.com/sony/nnabla-nas
- Python Package hosted on PYPI, install with:
pip install -U nnabla-nas
Key Features
Search Space
- Flexible way to define search spaces
- Efficient sampling of architectures from search space (fast)
- Predefined top level modules to define candidate architectures (e.g. inverted residual blocks, drop path, dilated depthwise separable, factorized reduction layer, etc.)
Search Algorithms
- Searcher algorithms to learn the architecture and model parameters (e.g.,
DartsSearcherandProxylessNasSearcher)
Hardware constraint
A key feature of NNabla NAS is the ability to search architectures with hardware constraint.
* Can be used to enforce hardware constraints (e.g. LatencyEstimator and MemoryEstimator)
* NNabla NAS implements online latency profilers for CPU and GPU and offline profiling for other devices (getting latency from look-up table)
Other Features
- Logging and visualization based on the tensorboard (https://www.tensorflow.org/tensorboard/get_started)
- Graph visualization of networks and search spaces
- Multi-GPU Support
- Image Augmentation with NVIDIA DALI (https://developer.nvidia.com/DALI)
Quick Start
Install
First you need to install NNabla with the configuration that suit your environment. Follow the instruction from https://nnabla.org/download/ . E.g, if you have cuda 10.2:
pip install -U nnabla-ext-cuda102
To install NNabla NAS, simply run the following pip install in an environment with python >= 3.6
pip install -U nnabla-nas
DARTS Architecture Search
This simple script runs DARTS architecture search [Liu18]
import nnabla as nn
from nnabla.ext_utils import get_extension_context
from nnabla_ext.cuda import StreamEventHandler
from nnabla_nas import runner
from nnabla_nas.utils.helper import CommunicatorWrapper
from nnabla_nas.contrib.classification import darts
from args import Configuration
# set the hyper parameters
hparams = {'batch_size_train': 64,
'batch_size_valid': 64,
'mini_batch_train': 16,
'mini_batch_valid': 16,
'epoch': 50,
'search': True,
'target_shapes': [[1]],
'algorithm': 'DartsSearcher',
'config_file': 'examples/classification/darts/cifar10_search.json',
'output_path': 'log/classification/darts/cifar10/search',
'device_id' : 0,
'context': 'cudnn',
'device_id': '0',
'type_config': 'float'}
# split the training set in half for training model and architecture params
data_params = {'train_portion': 0.5}
# set model params training optimizer
train_opt_params = {'grad_clip': 5.0,
'lr_scheduler': 'CosineScheduler',
'weight_decay': 0.0003,
'name': 'Momentum',
'lr': 0.025}
# set architecture training optimizer
valid_opt_params = {'grad_clip': 5.0,
'weight_decay': 0.0003,
'name': 'Momentum',
'lr': 0.025}
# setup context for nnabla
ctx = get_extension_context(hparams['context'],
device_id=hparams['device_id'],
type_config=hparams['type_config'])
hparams['comm'] = CommunicatorWrapper(ctx)
hparams['event'] = StreamEventHandler(int(hparams['comm'].ctx.device_id))
nn.set_default_context(hparams['comm'].ctx)
# set configurations
config={}
config['dataloader'] = {'cifar10' : data_params}
config['optimizer'] = {'train' : train_opt_params, 'valid' : valid_opt_params}
config['hparams'] = hparams
conf = Configuration(config)
# generate darts search space
model = darts.SearchNet(in_channels=3, # RGB input
init_channels=16, # output of the first convolution
num_cells=8, # number of cells of the darts search space
num_classes=10, # CIFAR10 has 10 classes
shared=True) # share architecture parameters between cells
# start the search
runner.DartsSearcher(model,
optimizer=conf.optimizer,
dataloader=conf.dataloader,
args=conf.hparams).run()
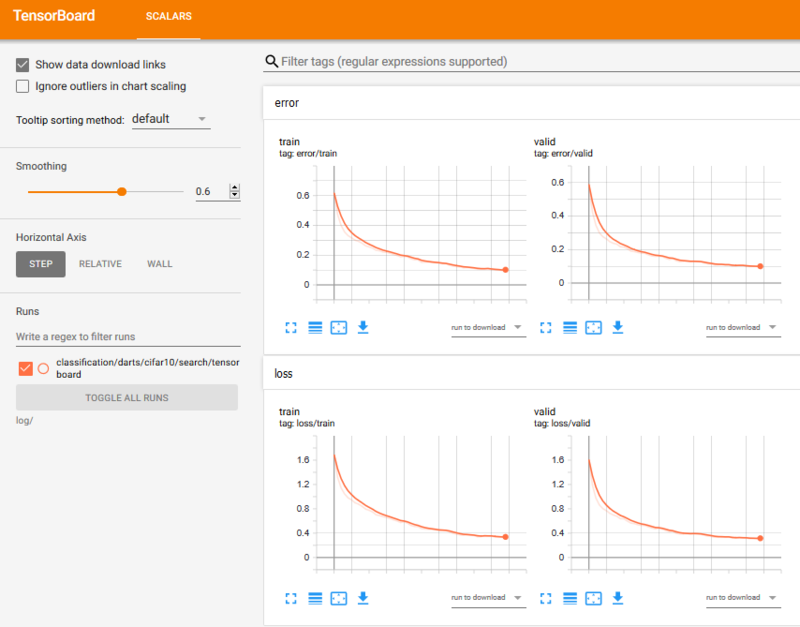
Monitoring
You can start the tensorboard server as follows:
tensorboard --logdir='log/'
(The logs will start after the first epochs)
For more details about the tensorboard, please refer to https://www.tensorflow.org/tensorboard/get_started
References
[Cai19] Cai, Han, et al. “On-device image classification with proxyless neural architecture search and quantization-aware fine-tuning.” Proceedings of the IEEE International Conference on Computer Vision Workshops. 2019.
[Liu18] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. “Darts: Differentiable architecture search.” arXiv preprint arXiv:1806.09055 (2018).
[Sandlers18] Sandler, Mark, et al. “Mobilenetv2: Inverted residuals and linear bottlenecks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.