We have released Neural Network Libraries v1.20.0!
Also, nnabla-rl, a new library for deep reinforcement learning by nnabla, has been released! For more details, please check this article!
Furthermore, the inference code and colab demo for Sony’s CVPR2021 paper D3Net are now available at ai-research repostiory!
Spotlight
Support forward recomputation in backward propagation (CPU / GPU)
We have implemented a functionality for training that deletes the intermediate buffer during forward computation, and recomputes the data required during backward computation. This functionality reduces the memory usage for training at the cost of additional training time.
x = nn.Variable(...) # input
t = nn.Variable(...) # label
# first layer
h1 = PF.affine(x, c1)
h1.apply(recompute=True) # <- set recompute flag as True
# second layer
y = PF.affine(h1, c2)
loss = F.mean(F.squared_error(y, t))
# h1 will be cleared during forward.
loss.forward(clear_no_need_grad=True)
# Backward of the second affine layer requires h1,
# so h1 will be recomputed before executing its backward computation.
loss.backward(clear_buffer=True)
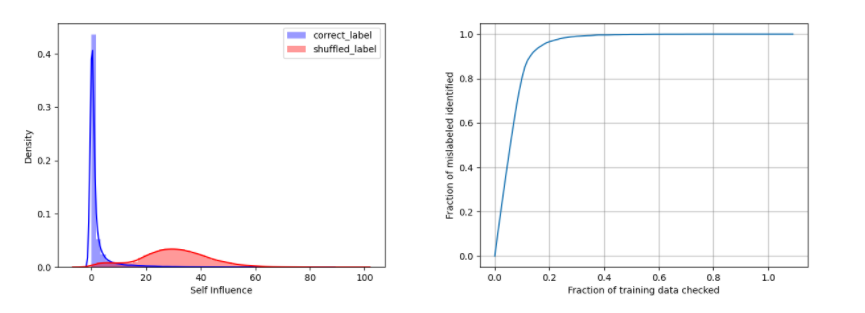
TracIn / eXplainable AI
We have implemented TracIn that computes the training data’s self-influence by tracining gradient descent. TracIn enables you to detect mislabeled samples.
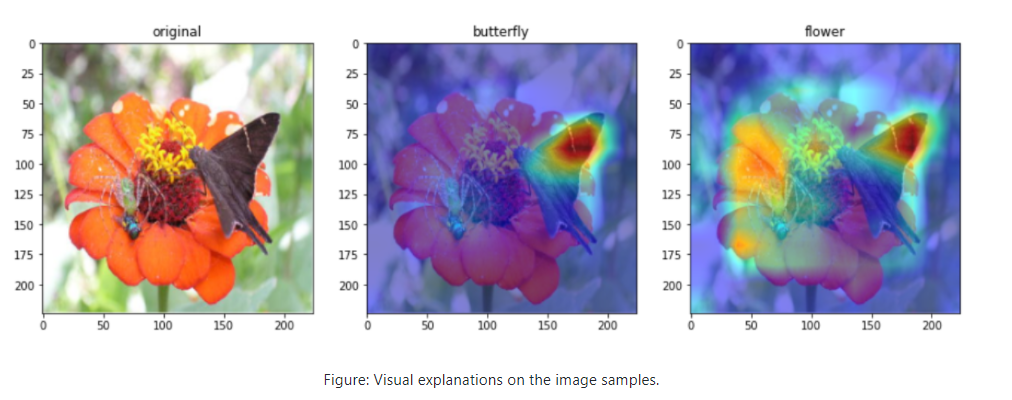
Grad-CAM/eXplainable AI
We have added Grad-CAM, a model for eXplainable AI (XAI) that produces visusal explanation for decisions in image classification. It displays characteristic regions as heat map for CNN-based deep learning models. You can also try it with our colab demo!
Add Colab Demos for SLE-GAN / TecoGAN
We have added new Colab interactive demos for SLE-GAN, a few-shot image generation model, and TecoGAN, a video-superresolution model.
You can access the demos from below:
| Name | Notebook | Task | Example |
|---|---|---|---|
| SLE-GAN | Image Generation |  |
|
| TecoGAN | Video Super-Resolution |   |
No grad context and converter
We have implemented no_grad, which allows you to skip gradient computation at a certain part of the network! For example, you can import pre-trained weight parameters for a part of the network without updating the parameters (in other words, gradient computation is unnecessary), while allowing only the other part of the network to proceed with training. More efficient memory usage is possible.
# when gradient computation is not necessary
with nn.no_grad():
output0 = <Network0>(<input0>)
# when gradient computatin is necessary
output1 = <Network1>(<input1>, output0)
loss = <Loss>(output1, <ground_truth>)
loss.forward(clear_no_need_grad=True)
You can also use it for dynamic graphs.
with nn.auto_forward(), nn.no_grad():
output0 = <Network0>(<input0>)
For static graphs that have already been defined, you can enable it to skip gradient computation as follows:
x = nn.Variable.from_numpy_array([2, 3])
y = <Network>(x).no_grad()
This is particularly useful when using networks imported from .nnp files.
Add converter that directly converts nnp to tflite
We have implemented a new converter to convert .nnp to tflite directly.
It no longer depends on onnx_tf as in the old converter, and it can handle network’s data format more flexibly.
You can use the converter as following:
nnabla_cli convert -b 1 input.nnp output.tflite
| Model structure with nnabla | tflite model converted with our new converter |
|---|---|
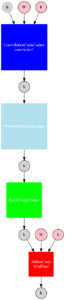 |
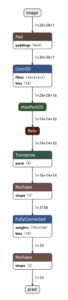 |
Change of Initial Settings
Bugfix
- fix: slove the bug that duplicated ID 331 and 332 in functions.yaml
- Fix RandomShift class initialization order issue
- Fix Conv1d of ONNX exporter and set the default opset to 11.
- Fix problems with incorrect graph/parameters
- Fix load BytesIO failure.
- Fix buffer overrun with cudnnBatchNormalizationForwardTraining
- Fix issue with softplus
- Sync between device and host after warm-up in GraphProfiler
- Bug fix of fused binary operator (CPU / GPU)
- Bugfix: forward(clear_no_need_grad=True) and nn.grad of Dropout (CPU / GPU)
- Fix recompute to check if data is cleared before backward without setup_recompute
Build
Core Functionalities
Layers
- Modify SoftPlus to accept beta argument (CPU / GPU)
- Searchsorted and Meshgrid implementation (CPU / GPU)
Utilities
- fix error when save network with F.mean()
- refactor: change audio_utils load resource behavior
- Allow parameter load and save in module
- Use urllib instead of requests (CPU / GPU)
- Enable the support of module for viewers
- fix nnpload no variable name problem
- Add target of install converter