FairNAS(Chu et al. ICCV2021) and Once-for-All (OFA)(Cai et al. ICLR2020)are now available in NNablaNAS! They are simple yet effective super-net training schemes for one-shot neural architecture search (NAS).
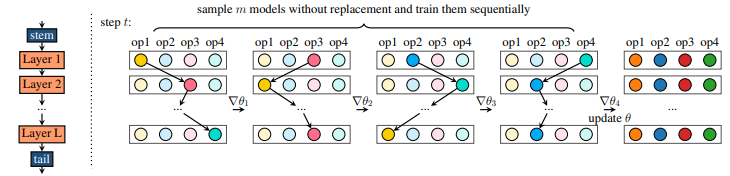
FairNAS
A known problem of one-shot NAS algorithms is that the super-net performances are heavily influenced by the applied training scheme. One-shot NAS algorithms often randomly drop some components of the super-net, such as parameters, layers, channels, etc., during training and only adapt a subset of the network parameters to obtain a super-net that is robust with respect to architectural changes. FairNAS uses a special random dropout scheme that ensures: 1) “expectation fairness” and 2) “strict fairness” for the network parameter updates. More specifically, strict fairness ensures that each network parameter has equal optimization opportunities. This helps yield super-nets that are better suited for highly accurate architecture ranking.
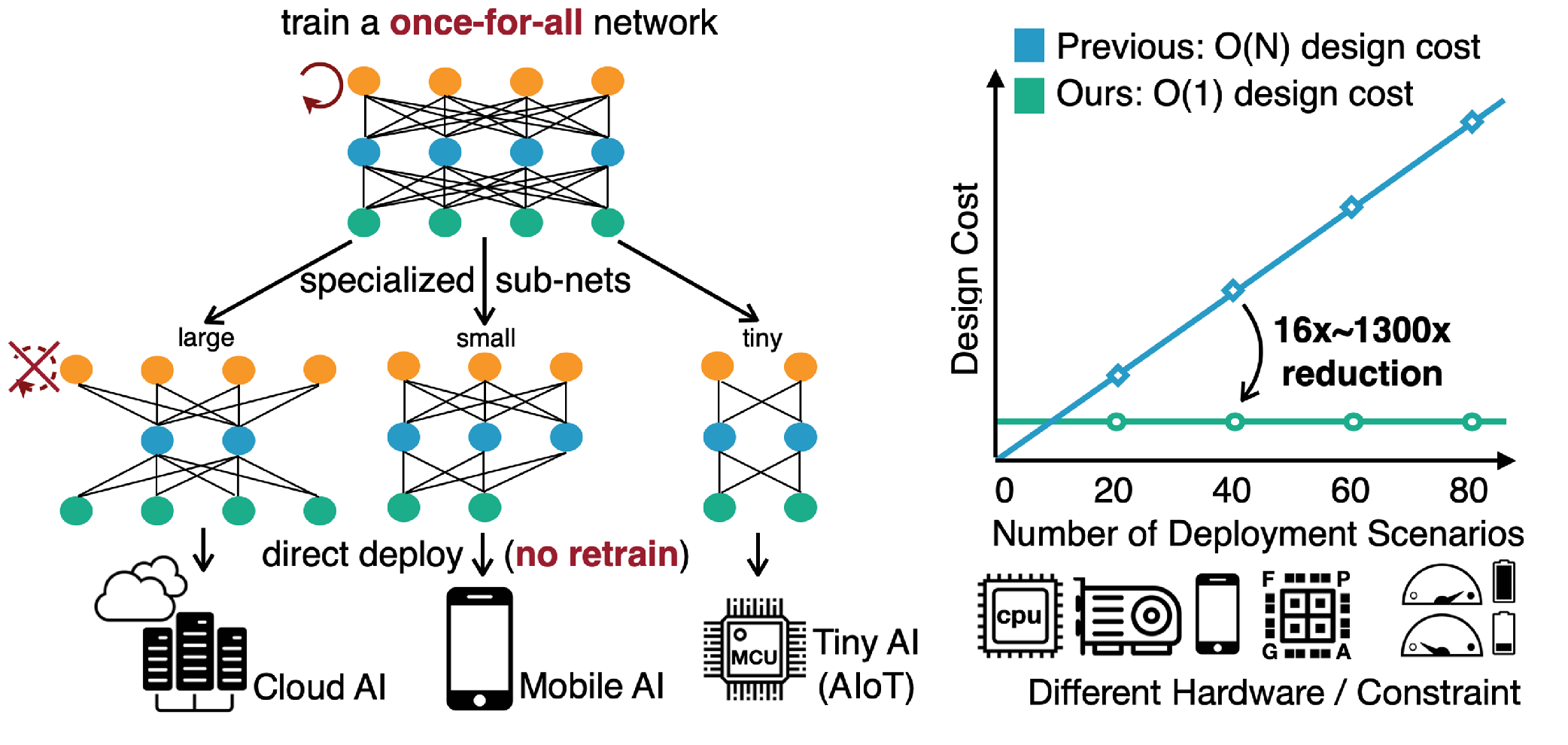
OFA
OFA is only trained once, and we can quickly get specialized sub-networks from the OFA network without additional training. It decouples training and searching to reduce the computation cost. The OFA search space contains a large number of sub-networks (>10^19) that covers various hardware platforms. The search space includes resolution, kernel size, width expansion ratio, and depth, encompassing important dimensions of the CNN architectures. To efficiently train the search space, the progressive shrinking algorithm enforces the training order from large sub-networks to small sub-networks in a progressive manner.
In NNablaNAS, FairNAS and OFA are implemented and can be selected as a search algorithm for one-shot architecture search. Furthermore, we provide examples demonstrating how to use it to find optimized DNN architectures for the task of visual object recognition.